Nebula is not the fastest mesh VPN
(But neither are any of the others)

When have you seen a vendor or developer publish benchmarks where their product or project was represented as being on par with (or behind) its direct competitors? There must be examples of this, but I’m struggling to come up with any. Regardless, why would anyone choose to do this? I hope this article clarifies why we are publishing these results and helps clear up some very common misconceptions about performance.
The first section describes the how and why, but if you want to skip to the results, feel free. I would encourage you to refer to the earlier sections if you want clarification on this rather complex topic.
Background
We started developing Nebula in early 2017, and open sourced it nearly 3 years later, at the end of 2019. Because we built Nebula within Slack, a company that was growing quickly, we were forced to consider scale and reliability from the beginning.
You might be surprised to learn that we’ve also been benchmarking Nebula against similar software since <checks notes> October of 2018, according to this git commit:
These benchmarks have been a valuable method of validating major changes we’ve made to Nebula over the years, but have also helped us see where we stand compared to our peers. As the space has evolved, we’ve seen results improve for nearly all of the offerings we test against. For our own purposes, we also benchmark Nebula against older versions of Nebula to ensure we catch and resolve things like memory leaks or unexpected CPU use between versions. When your software connects the infrastructure of a service millions of people depend on, it is important to do performance regression testing. Consistency and predictability in resource use and performance are things we value.
Despite the fact we’ve been doing this for years, there is no good public version of data like this. In the cases where benchmarks seem to exist, they are generally dreadfully unscientific, or they are point-in-time snapshots, as opposed to an ongoing effort. There are smart people improving mesh VPN offerings all the time, but no one is tracking their progress as it happens. We aim to change that by opening our benchmarking methodology to public review and contribution.
I recommend you read the paper “Fair Benchmarking Considered Difficult: Common Pitfalls In Database Performance Testing” from Centrum Wiskunde & Informatica (CWI), authored by Mark Raasveldt, Pedro Holanda, Tim Gubner & Hannes Mühleisen. It is absolutely brilliant and worth your time. The title mentions database, which is their particular expertise, but the paper itself makes excellent points that are applicable to all benchmarking. Figure 1 is so accurate, that it made me laugh out loud.
Figure 1: Figure 1 from paper “Fair Benchmarking Considered Difficult: Common Pitfalls In Database Performance Testing”
Our Guidelines for Meaningful Benchmark Testing
We’ve put a lot of thought into how to make our testing useful and fair over the years. Here are some of the most important guidelines we follow in our testing:
-
Be as objective as possible. Although we are quite fond of Nebula, we aim to be as objective as possible regarding this testing these results. For years these tests have only been used internally, so there is no incentive to manipulate or distort the data. This has always been for our benefit and will continue to be an extremely valuable part of our testing process.
-
Buy some hardware. In the beginning, we made the same mistake as everyone else, by trying to get meaningful and reproducible benchmark numbers by spinning up hosts at various cloud providers. To be fair, this may be useful to test changes to your codebase, if you accept the very real caveats to such testing. It is a terrible way to compare software from different vendors, if your goal is accuracy. We have extensive experience running Nebula at a massive scale on hosts at various cloud providers, and the only consistent thing we’ve seen is the inconsistency of the results. A few years ago, we purchased five very boring Dell desktop computers, with relatively boring i7-10700 CPUs, and we installed 10 gigabit network interface cards in each of them, connected to a switch that cost more than any of the computers. Testing is done by netbooting fresh OSes every single time we run our benchmarks. We generally boot the latest LTS release of Ubuntu before every round of testing. Our results are repeatable and consistent, and we run multiple rounds of the same test to validate the results.
-
Detune the hardware so you aren’t fighting thermal issues. CPUs and cooling solutions can have a lot of variability, so if the chip fab was having a bad day, or your fan has a blade with an invisible turbulent crack it is very possible for two “identical” boxes to perform differently once you reach the top end. To remove this, we have disabled some of the speed states that can result in inconsistent performance. Hyperthreading is also disabled on these hosts.
-
Test multiple streams between multiple hosts. When evaluating mesh VPN software, you should be transmitting and receiving traffic from all of them concurrently. There are a surprising number of new and different performance characteristics that emerge once you involve multiple hosts. Often, when someone posts benchmarks, you’ll see them spin up two hosts and use a single iperf3 stream between them, but that is of limited value. For one thing, occasionally iperf3 is using a full core, and iperf3 becomes the bottleneck. This can make for nonsensical results. (Author’s opinion: iperf3 is a remarkably easy to use and useful tool, which is a blessing and a curse.) If you are using a mesh VPN, you probably have more than two hosts communicating at any given time. Honestly, if you only care a point-to-point connection, use whatever you like. Wireguard is great. IPsec exists. OpenVPN isn’t even that bad these days.
-
Compare functionally equivalent things. Historically, we benchmarked Nebula against both Mesh VPN software, such as ZeroTier and Tinc, but also against classical VPNs, such as Wireguard and OpenVPN. There were less offerings in the space, but that has changed significantly in the past few years. The goals of Nebula and Wireguard are quite different, and Wireguard doesn’t concern itself with things like ACLs or host identity. This article and subset of our testing is purposefully limited to things functionally equivalent to Nebula, to avoid inevitable lengthy explanations about the differences between dissimilar software.
-
Level the playing field. Every single one of the mesh VPN options tested here uses a different default MTU. There is nothing wrong with this, but the only way to meaningfully compare performance between these offerings is to set a lowest common denominator packet size. The applications you use will determine how much data they send at a given moment, not you, so assuming they will always send packets that take full advantage of a large MTU is unlikely. We’ve gone back and forth between an effective MTU of 1240 and 1040 various times over the years, by employing MSS Clamping within iperf3. As you’ll see in the results, the most relevant metric is generally packets per second. As you scale up and down through various MTU options, the peak number of packets per second remains the bottleneck. Most networking hardware vendors speak in these terms, and ultimately, the number of packets you can transmit and receive in a particular timeframe is the only thing that matters.
-
Never comingle the software you are testing on a host. I have witnessed some absurdly bad results due to sloppy testing. Most mesh VPNs continuously try to discover new paths between peers. If you happen to run two of them at once, and don’t tell them to exclude each other as a viable path, you can end up sending, for instance, Nebula traffic through a ZeroTier tunnel. I’ve accidentally done this myself, in fact. Additionally, some mesh VPNs modify routing tables, add iptables rules, and do all manner of things to the host system that may affect the next test. These are variables that should be eliminated.
-
Learn to tune everything, not just your thing. Over the years, we’ve invested a lot of time in understanding the performance characteristics of everything we test. There is usually no incentive to learn how to make your competitor’s software perform well, but in our case, we want to know if it is happening and learn from those results. A suite of tests where you tune your thing and ignore everything else is dubious.
-
Have fun. Just kidding. This has been a lot of hard work over the years. It is interesting, but we (I) wouldn’t say it is particularly fun.
Mesh VPNs Compared
For this first public release of data, we’ve chosen to test the most popular mesh VPN options we’re aware of, so we will be comparing Nebula (in AES mode), Netmaker, Tailscale, and ZeroTier (note, this list is intentionally in alphabetical order, as additional confirmation of our commitment to fairness). There is an extremely important caveat to consider when comparing these options, due to its performance implications. Only Nebula and Tailscale directly implement stateful packet filtering. You can use either of them without applying additional rules on the virtual network interfaces associated with their their mesh overlay. ZeroTier’s stateless firewall is more limited in capability, but a discussion of the merits of stateful vs stateless packet filtering out of scope for this writing.
Netmaker has something called “ACLs”, but in reality, they can only prevent entire hosts from talking to each other. They cannot be used to specify specific ports or protocols. Netmaker recommends that you use iptables or similar for fine grained control. It might be assumed that iptables is fast enough to be effectively “free”, but this is absolutely not the case. Even a single stateful conntrack rule on the INPUT chain can impact performance to the tune of about 10% in our testing. We decided not to use such a rule when testing Netmaker here, despite the fact that most large deployments would and should use fine grained filtering of traffic between hosts.
Suggestions Welcome
A case might be made for us to include (insert another project here), but most others are still based on Wireguard or Wireguard-go. We will consider requests to add other projects based on Wireguard if folks are willing to send us evidence of another option performing substantially differently than a similar option we have tested here.
These benchmarks are meant to be used as an ongoing record of performance. We will settle into a cadence for publishing/comparing things, once we get a feel for the demand for this information. This is a time-intensive task, so there will be limits, but the configurations, test parameters and command lines, and raw results from the tests will be made available on GitHub every time we do a round of testing. If the authors or users of any of these projects would like to help us further tune and refine our testing, we will gladly integrate any reasonable changes and benchmark new versions when possible.
The Tests
We’ve done several different tests over the years but have distilled this down to just three primary tests that allow us to usefully compare different mesh VPN options. We’ll describe the testing method used, and then show visualizations of the various results along with our interpretation of the data and any caveats.
Test 1: multi-host unidirectional transmit
Description: A single host transmits data to the other four hosts simultaneously with no predetermined rate limit for ten minutes. This test intentionally focuses on the transmit side of each option, so we can determine if there are any asymmetrical bottlenecks.
Method used: iperf3 [host2,3,4,5] -M 1200 -t 600
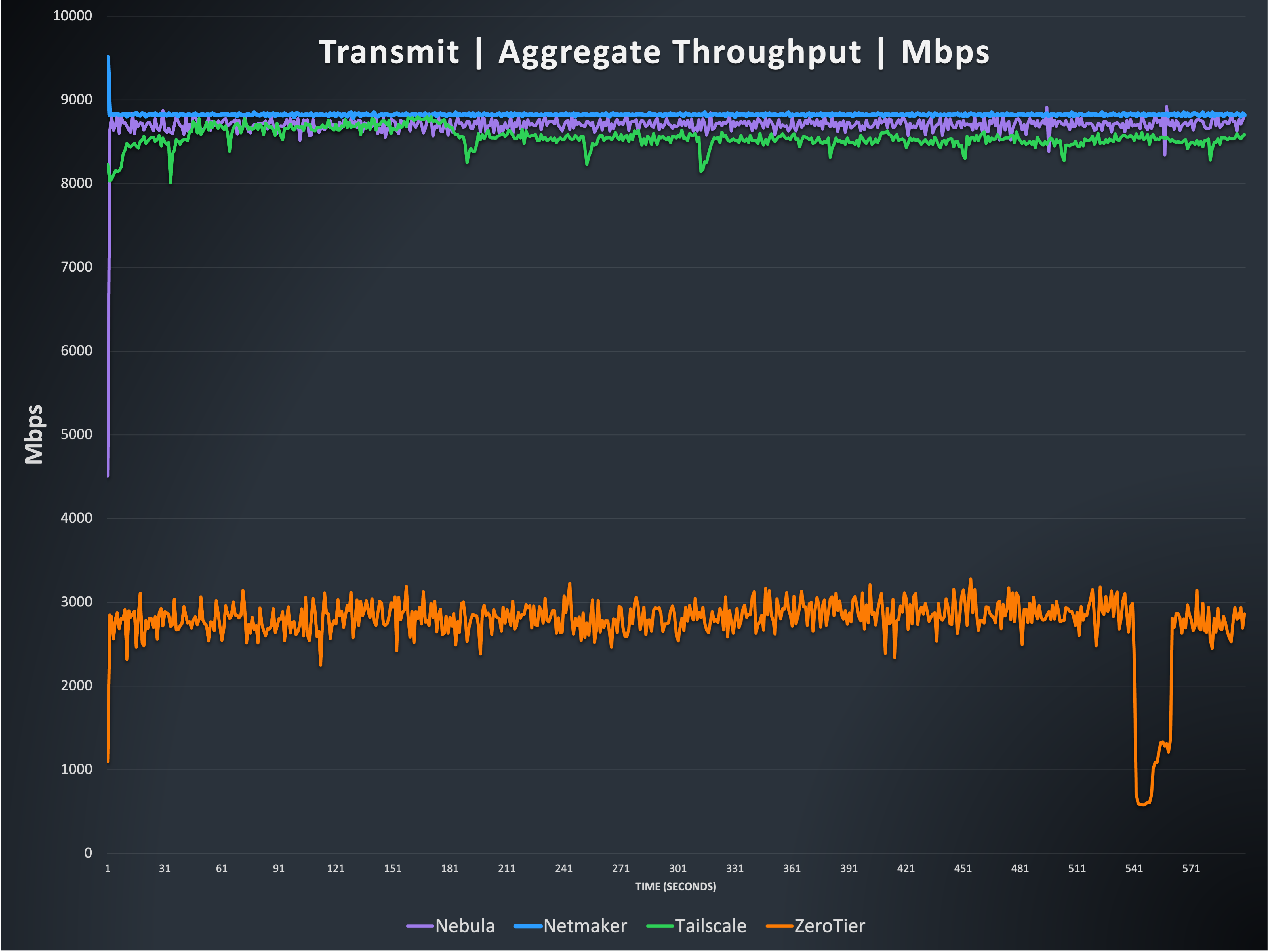
This graph shows three of the four options, Nebula, Netmaker, and Tailscale, can reach throughput that matches the limits of the underlying hardware, nearly 10 gigabits per second (Gbps). The fourth option, ZeroTier, is single threaded, meaning it cannot take advantage of hosts with a large number of CPU cores available, unlike the others. This results in ZeroTier’s performance being significantly limited, compared to the others. The Tailscale result is a bit more variable than the other two at the top, and you can see various short drops and slightly inconsistent performance, which is +/- ~900 Mbps over the course of the testing.
Note: The strange drop in ZeroTier does happen briefly on every transmit-only test we’ve done, though at different times. We have not yet determined the cause of these temporary throughput drops.
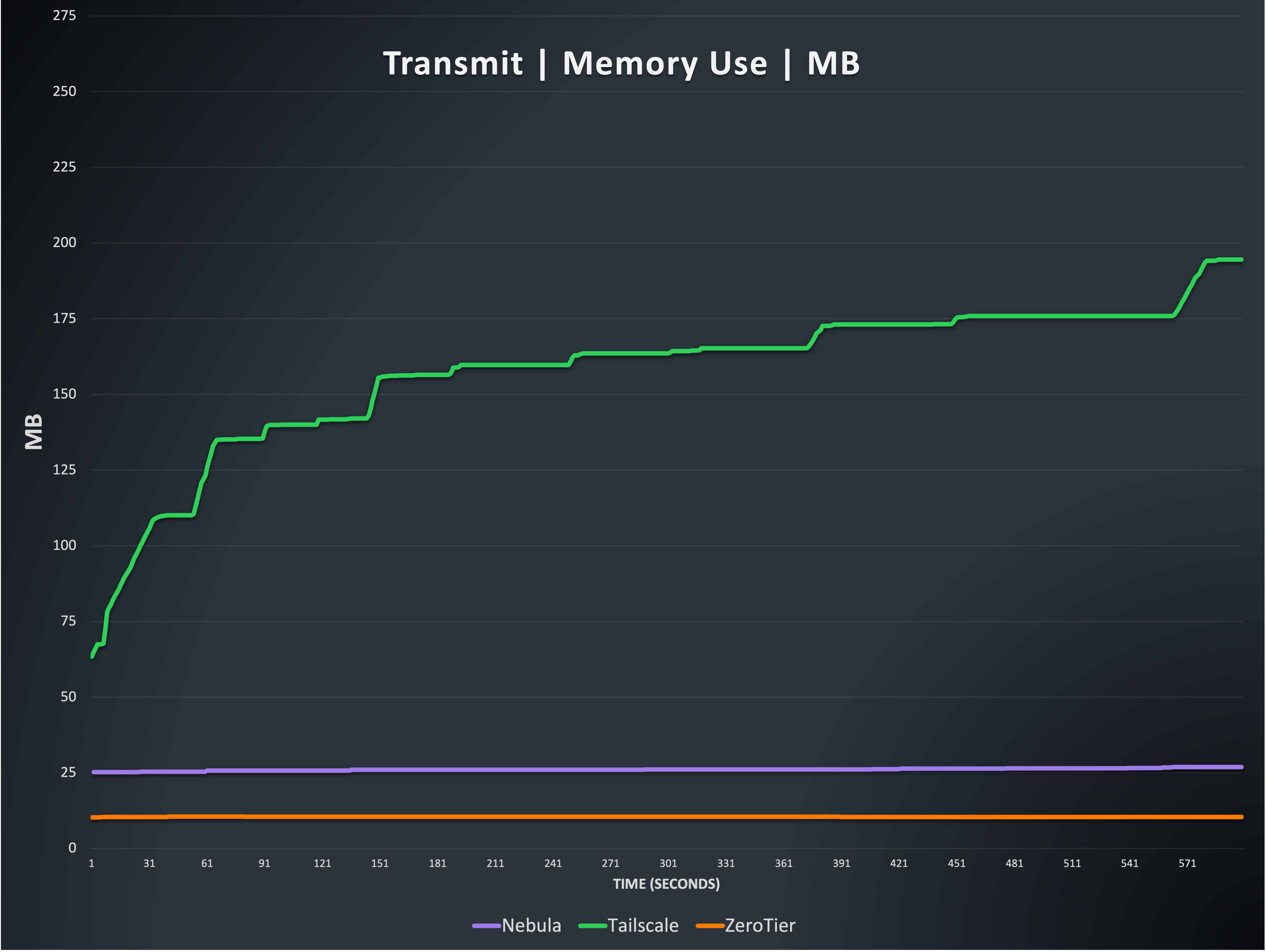
This is the total memory used by processes of three of the four options. Tailscale memory use is highly variable during our testing, and appears to be related to their efforts to coalesce packets for segmentation offloading. Some of this memory might be recovered through garbage collection after the tests, but this is also out of scope for this writing. We have seen memory use exceed 1GB during our tests, and the variability has been difficult to isolate. The memory results here are from the best case run we’ve recorded (where Tailscale used the least memory, compared to other runs).
Nebula and ZeroTier are extremely consistent in memory use, with almost no notable changes throughout testing. Nebula averages 27 megabytes of memory used, and ZeroTier averages 10 megabytes used.
Note: Because Netmaker on Linux uses the Wireguard kernel module, it is not possible to meaningfully collect data on its memory use, but it is generally efficient and consistent, from external observation.
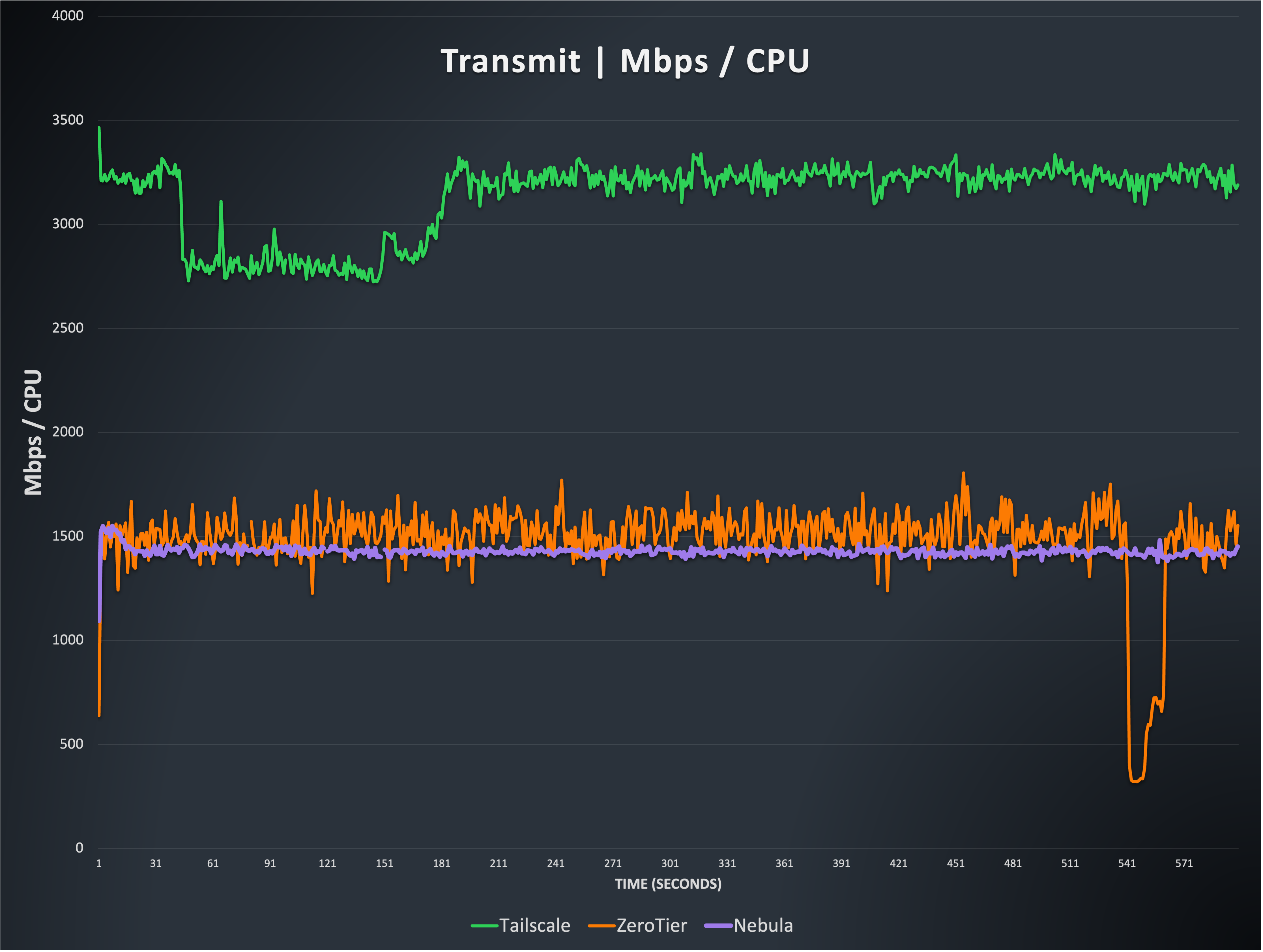
This graph shows the relationship between throughput and CPU resources. You can see that ZeroTier and Nebula are quite similar here, with ZeroTier being a bit more variable. Nebula scales very linearly with additional CPUs. The Tailscale result appears significantly better here, thanks to their use of various Linux segmentation offloading mechanisms. This allows them to use less syscalls in their packet processing path. It should be noted, however, that this does increase CPU use by the kernel, when dealing with these ‘superpackets’, so while segmentation offloading is certainly an efficiency boost, it is not as drastic as this makes it appear, when accounting for total system resources. Regardless, segmentation offloading is impressive and is what allowed Tailscale’s Linux performance to catch up to Nebula’s throughput numbers in early 2023. See note 1 at the end of this article for some important caveats regarding non-Linux platforms.
Note: Netmaker is again not included because it is hard to quantify kernel thread CPU use. It should be noted that it is quite similar to the others, and uses significant resources at these speeds.
Test 2: multi-host unidirectional receive
Description: Four hosts transmit data to an individual host as fast as possible for ten minutes. This test intentionally focuses on the receive side of each option, so we can determine if there are any asymmetrical bottlenecks.
Method used: iperf3 [host2,3,4,5] -M 1200 -t 600 -R
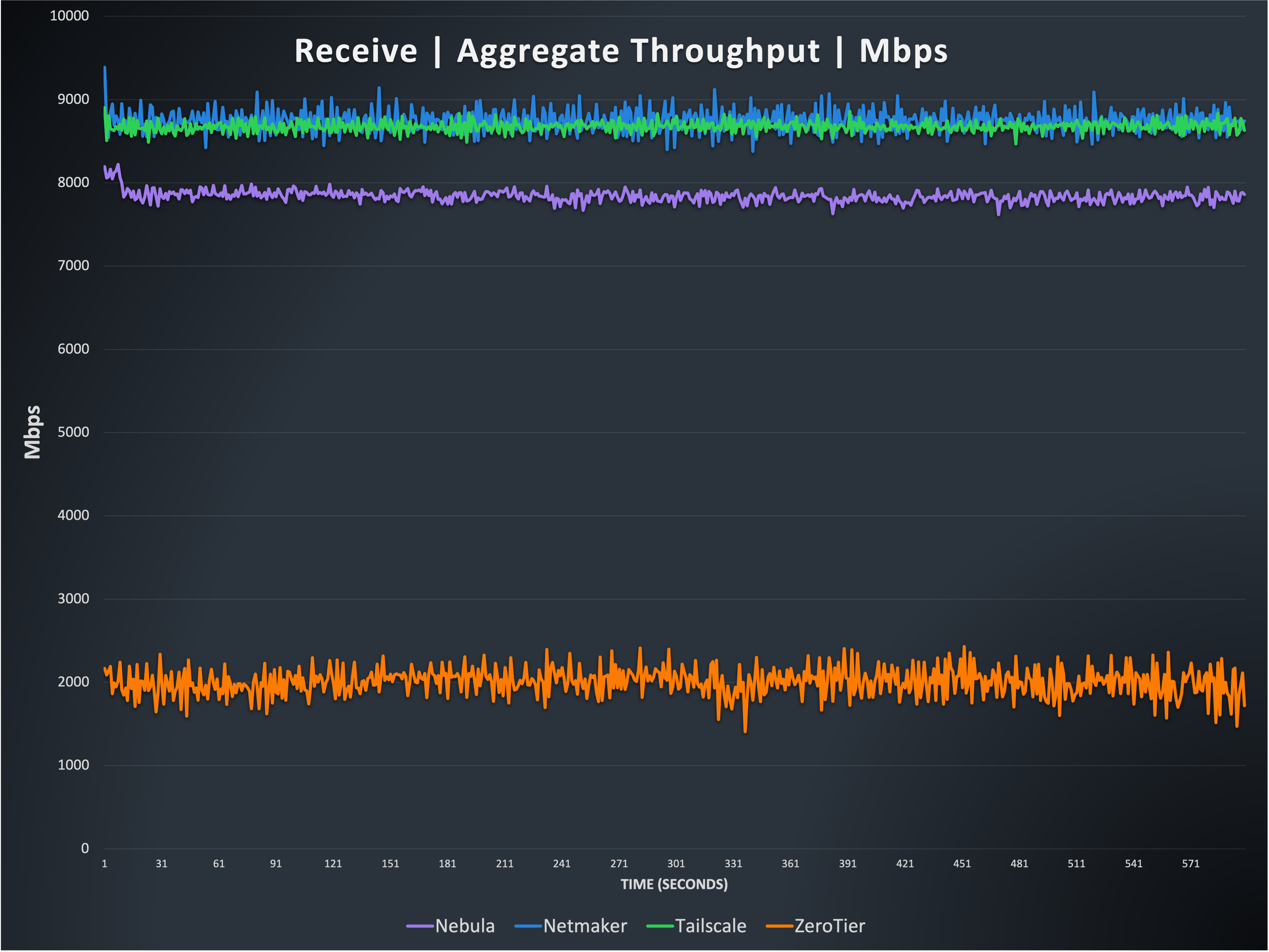
This graph shows two of the four options, Netmaker, and Tailscale, can reach throughput that matches the limits of the underlying hardware, nearly 10 Gbps. Compare the line for Netmaker with Figure 2 and you’ll see that on the receive side, Netmaker’s line is no longer flat. This is because it is CPU limited on the receive side, just like all of the other options. This is related to the receive side of kernel Wireguard having a different processing path style, which becomes a bottleneck. You can see that Nebula has fallen behind in this test, and is consistently about 900 Mbit/s behind the leaders. As before, ZeroTier is held back by its inability to use multiple CPU cores for packet processing.
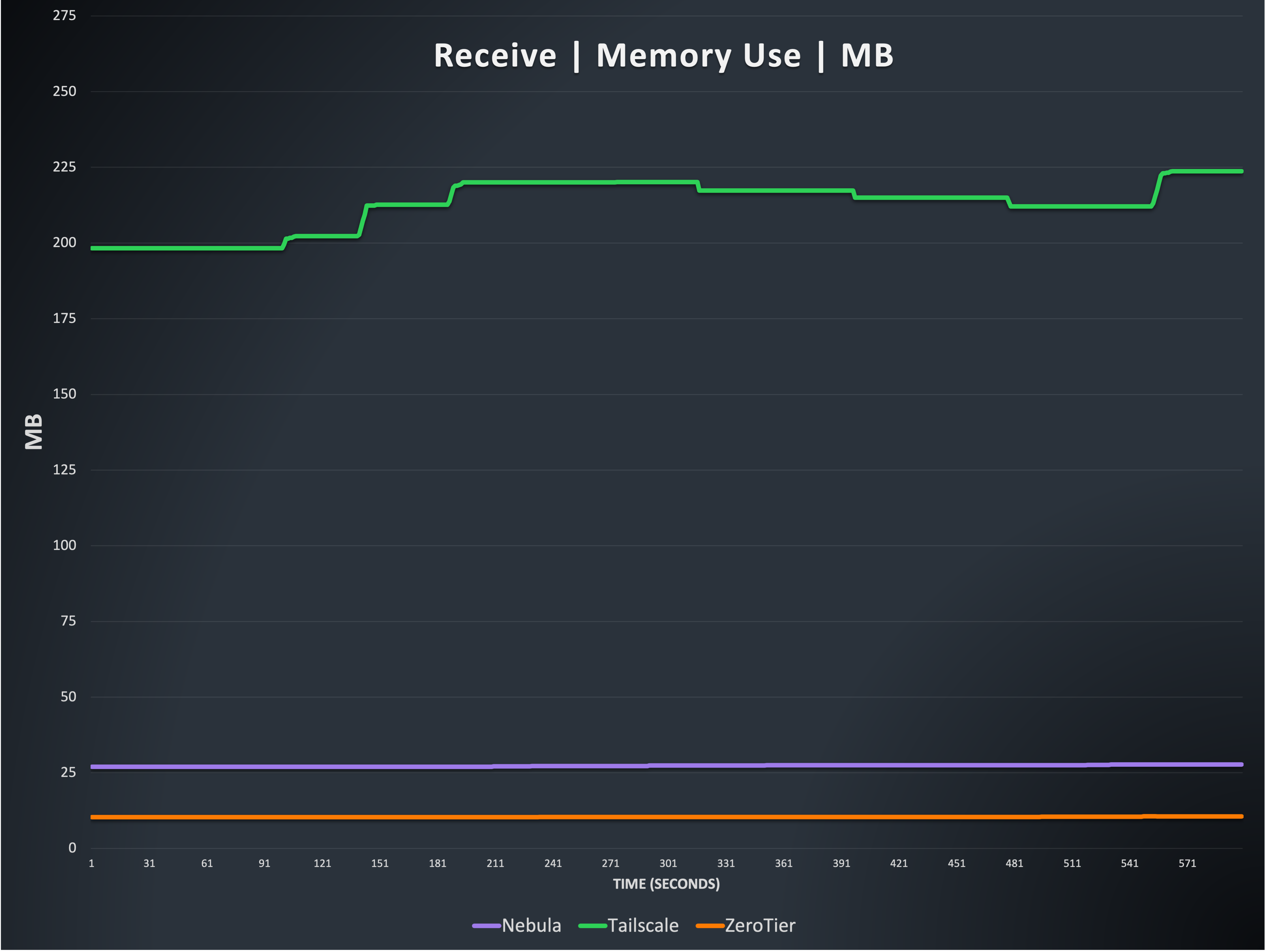
This is again the total memory used by processes of three of the four options, but for the receive side. Tailscale memory continues to be highly variable during our testing, though a bit less so when receiving. Once again, some of Tailscale’s memory use might be recovered through garbage collection after the tests, but this is also out of scope for this writing. The memory results here are again from the best case run we’ve recorded (where Tailscale used the least memory, compared to other runs).
Nebula and ZeroTier are extremely consistent in memory use, and again here we see no notable changes throughout testing. Nebula again averages 27 megabytes of memory used, and ZeroTier averages 10 megabytes used.
Note: Because Netmaker on Linux uses the Wireguard kernel module, it is not possible to meaningfully collect data on its memory use, but it is generally efficient and consistent, from external observation.
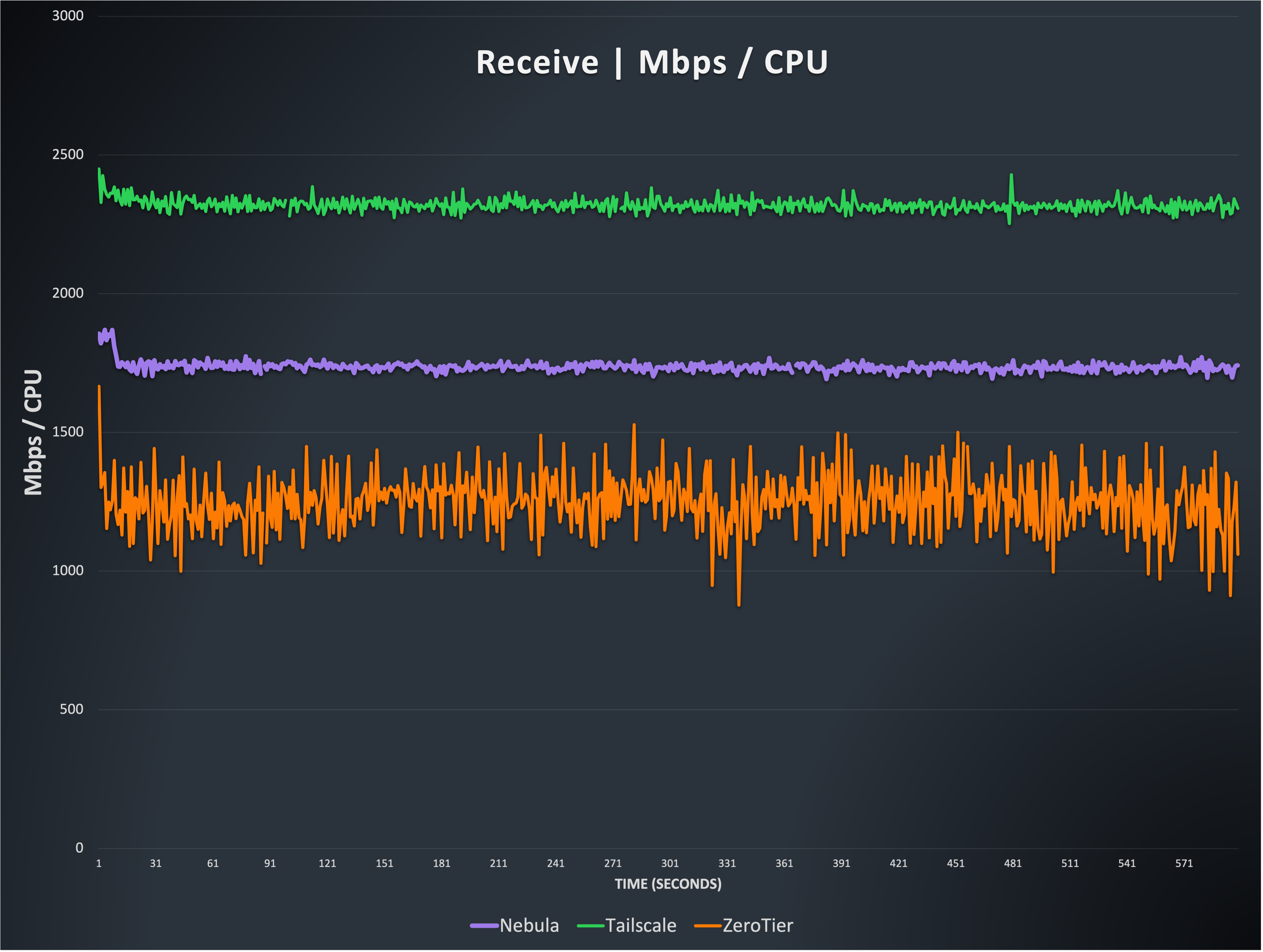
Similar to Figure 4, this graph shows the relationship between throughput and CPU resources. You can see that ZeroTier is quite similar to before, but Nebula appears to be more efficient. While this is true, it is similar to the reason Tailscale appears more efficient in Figure 4, because in this case, Nebula has long implemented the recvmmsg syscall, which shifts the burden slightly toward the kernel, but perhaps less substantially than segmentation offloading (further testing needed to confirm this).
The Tailscale result again appears significantly better here, thanks to their use of various Linux segmentation offloading mechanisms, but this is again thanks to shifting some of the burden of packet processing overhead into the kernel via segmentation offloading.
Note: Netmaker is again not included because it is hard to quantify kernel thread CPU use. It should be noted that it is quite similar to the others, and uses significant resources at these speeds.
Test 3: multi-host bidirectional transmit receive
Description: A single host transmits and receives data to/from the other four hosts simultaneously with no predetermined rate limit for ten minutes. This test intentionally combines the send and receive streams, so we can determine if there are any bottlenecks when a box is sending and receiving at its limit.
Method used: iperf3 [host2,3,4,5] -M 1200 -t 600 and iperf3 [host2,3,4,5] -M 1200 -t 600 -R are run simultaneously on host 1
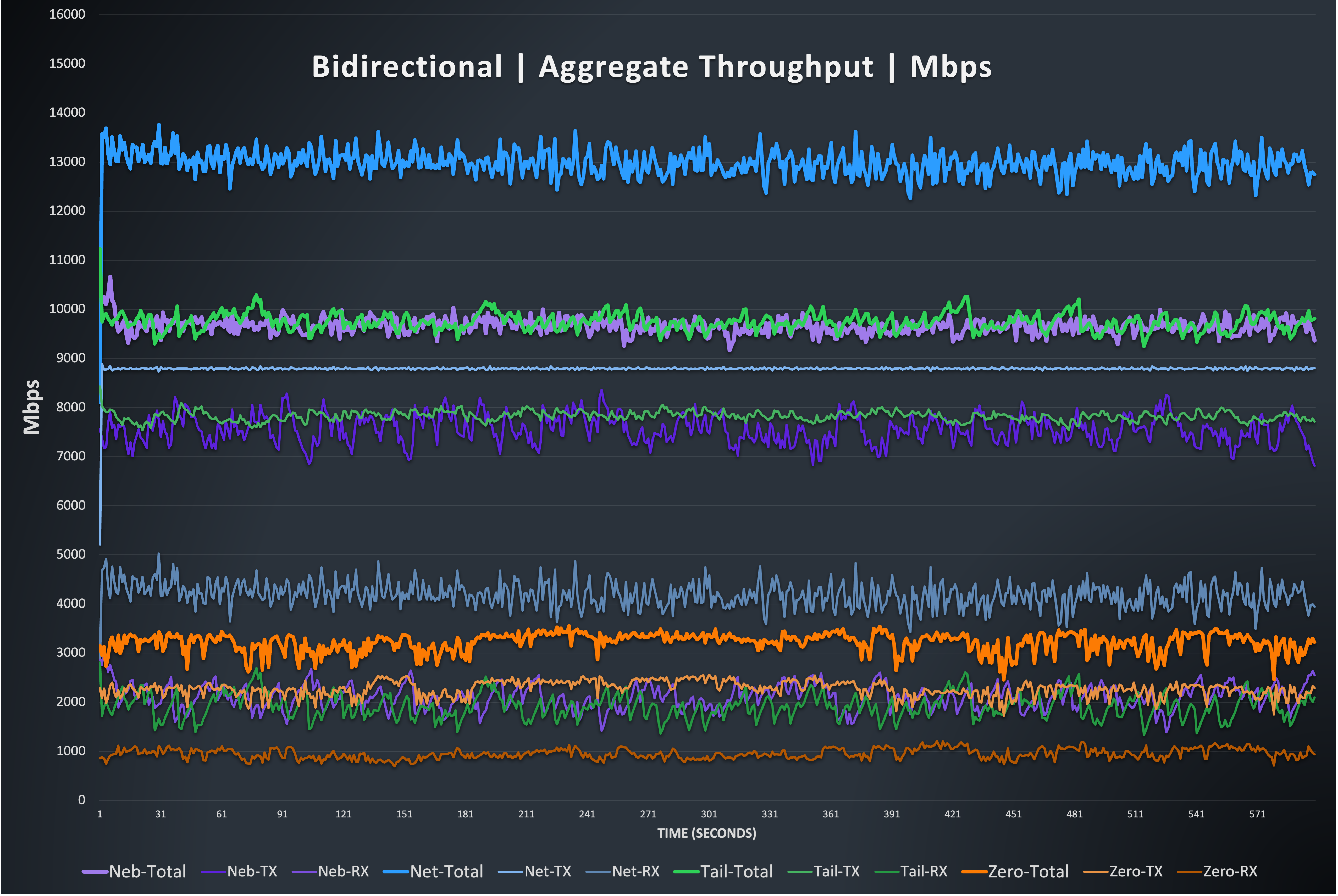
This graph shows independent lines for the simultaneous send/receive traffic, which are added to a total throughput number. It should be noted that the maximum achievable number here is between 19 and 20 Gbps, and you can see that none of the options achieve this performance. Netmaker achieves a total send/receive throughput average of ~13 Gbps, followed by Nebula and Tailscale roughly tied at an average of ~9.6 Gbps. ZeroTier again comes in behind the rest, but you’ll notice that it does have the ability to handle sending and receiving independently, and sees an improvement over the directional tests, averaging ~3Gbps.
Note: The strange drop in ZeroTier does not seem to happen during bidirectional tests.
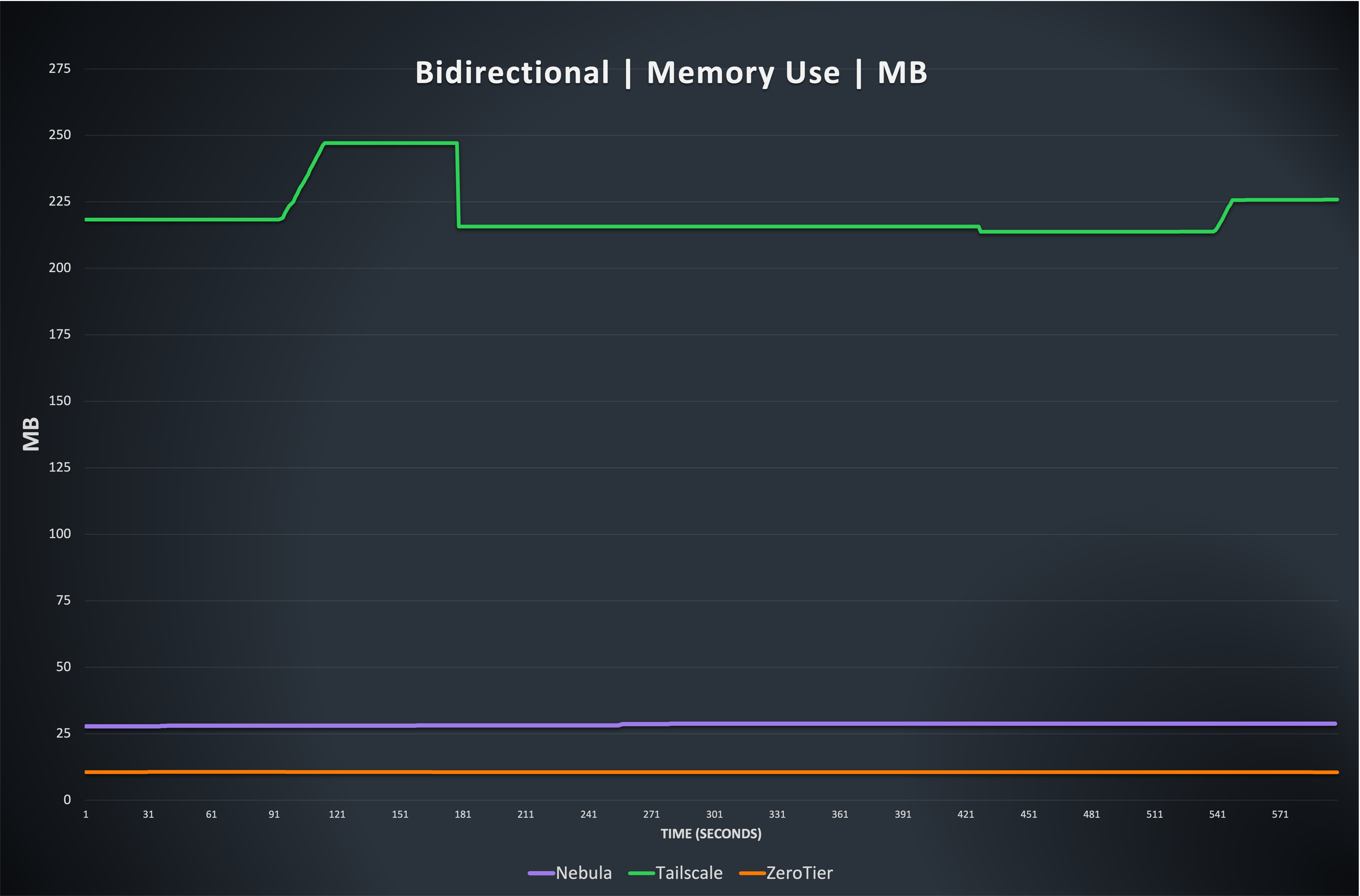
The results are consistent with previous memory use, with Nebula and ZeroTier using a consistent amount, and Tailscale being more variable and using significantly more memory to process packets.
Note: Because Netmaker on Linux uses the Wireguard kernel module, it is not possible to meaningfully collect data on its memory use, but it is generally efficient and consistent, from external observation.
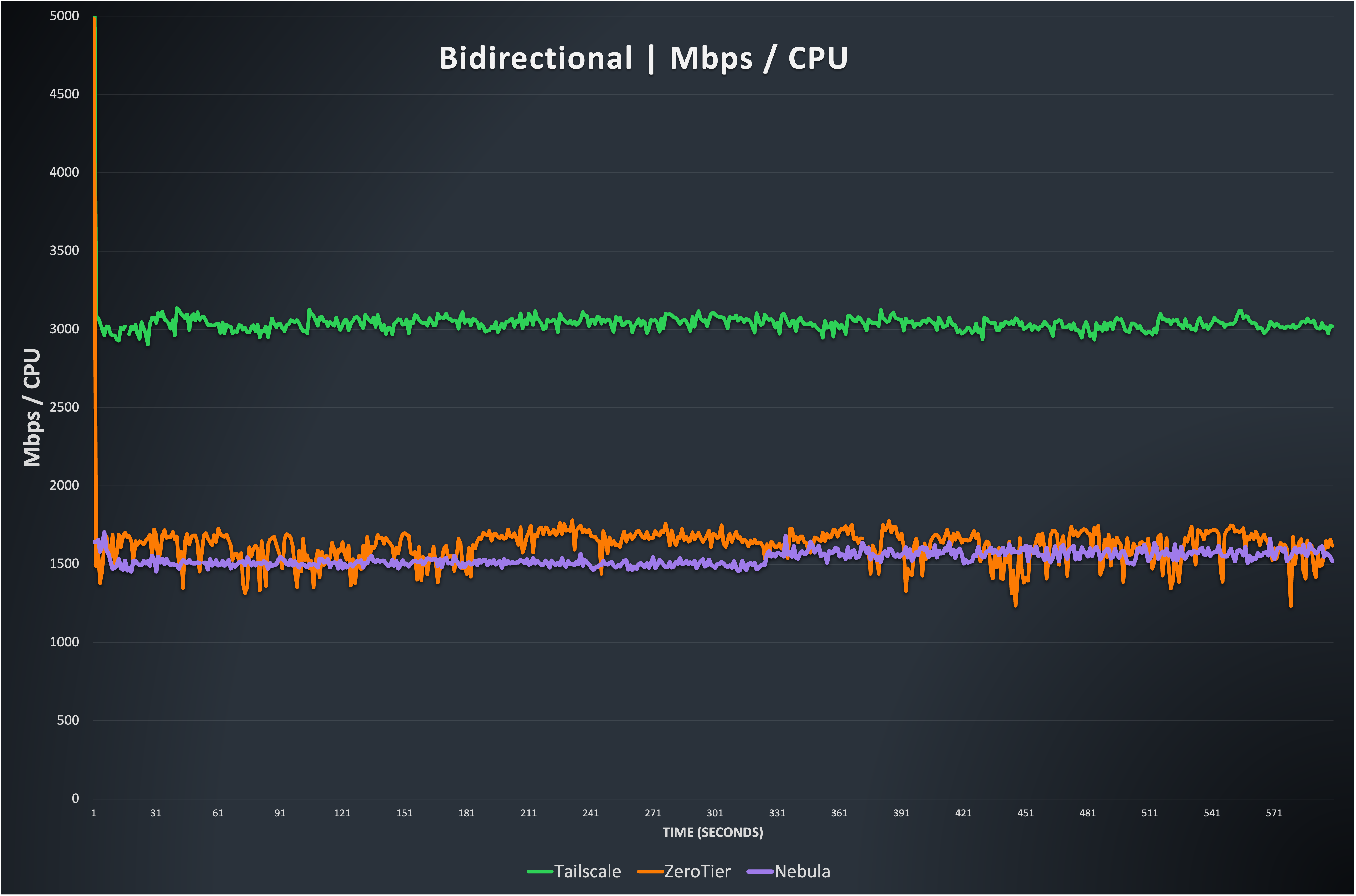
As in Figure 4 and Figure 7, this graph shows the relationship between throughput and CPU resources. You can see that ZeroTier is quite similar to before, as is Nebula. This test ends up being significantly more transmit heavy, so the results tend represent the transmit side more prominently Tailscale again appears more efficient, but with the caveat that the kernel is doing more work.
Note: Netmaker is again not included because it is hard to quantify kernel thread CPU use. It should be noted that it is quite similar to the others, and uses significant resources at these speeds.
Conclusion
There is no single “best” solution. Nebula, Netmaker, and Tailscale can realistically achieve performance that saturates a 10 Gbps network in a single direction on modern-ish CPUs, and tend to have quite similar profiles regarding total CPU use. Tailscale consistently uses significantly more memory than the rest of the options tested. (note: Historically Tailscale was pretty far behind, but segmentation offloading has allowed them to achieve much, much better performance, despite the high overhead of their complex internal packet handling paths.)
As noted above, only Nebula and Tailscale have stateful packet filtering, which is an important consideration here. If folks would like an updated version of this test showing the impact of iptables rules on Netmaker, please let us know. For now it was safer to give Netmaker a slight unfair advantage than try to explain the reason we might have added seemingly unnecessary iptables rules.
If your network is gigabit, ZeroTier is equally capable as the rest, with the lowest memory use of the three measured. It is quite efficient but held back by its lack of multithreading.
Finally, I guess we have to start sourcing 40 gigabit ethernet hardware, because the underlying network is now the limit in some tests.
Thank You + Additional Notes
A sincere “thank you” for taking the time to read this relatively dense performance exploration. If you read this hoping for a simple answer regarding the most performant mesh, I’m sure you are sorely disappointed. In fairness we did telegraph that this would be the case in the title of the article. The Github repository with the raw data and configurations will be available soon, and we are happy to run the tests again with reasonable suggestions for tweaking performance.
Bonus notes that didn’t fit anywhere in particular, but are included because perhaps someone will find them interesting:
-
Most of the performance optimizations implemented by these projects only affect Linux. Things like segmentation offload are not available as commonly on Windows and MacOS. While it is not in scope here, we have data that proves Nebula is significantly more efficient than wireguard-go (Which both Netmaker and Tailscale use on non-Linux patforms), and if folks care to see this data, we may write a followup article.
-
Depending on the underlying network, you can use higher MTU values to increase total throughput significantly. In AWS the default MTU is 9001, so Nebula’s MTU is 8600. But another important detail: when you leave an AZ your MTU drops to 1500. If you send a large Nebula packet it will become fragmented. AWS (and others) rate limit fragmented packets aggressively, so watch out for that. Nebula has a built in capability where different network ranges can use different MTUs, which allows you to take advantage of large MTUs internally on an AZ but default to smaller ones elsewhere.
-
We have excluded Tinc from the results, simply because it is rarely competitive, performance-wise. I respect Guus Sliepen and the work folks have done on Tinc for years, and was a happy user well into the mid 2010s, but it is not competitive performance-wise. Additionally, it has some internal routing features that are novel and not replicated by any of the other options.
-
The Raspberry Pi 5 is the first Pi that supports AES instructions, and Nebula in AES mode easily saturates gigabit without using more than a single core.
-
It can be hard (or impossible) to evaluate kernel based options directly, since kernel thread are not as easy to measure as userspace. This is why we do not have memory use numbers for kernel Wireguard (Netmaker). We could probably get somewhat close by indirect observation, but we aren’t confident in that being accurate enough for our purposes.
-
I own a Lightning Ethernet adapter because I wanted to remove the variability of WiFi from the testing on iOS, but the Lightning Ethernet adapter has much more variability than Wifi. So, that’s fun.
Nebula, but easier
Take the hassle out of managing your private network with Defined Networking, built by the creators of Nebula.